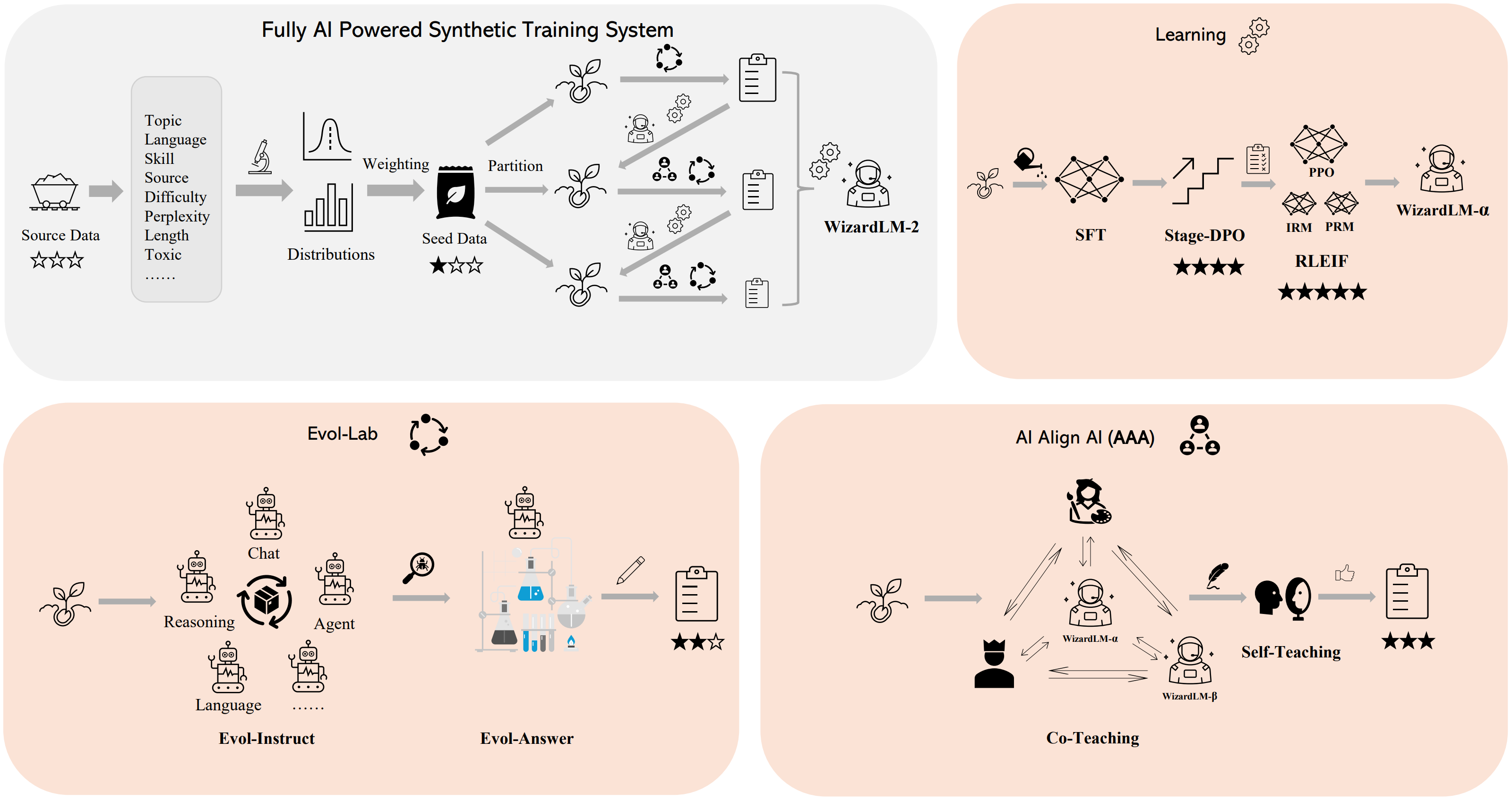
We introduce and opensource WizardLM-2, our next generation state-of-the-art large language models, which have improved performance on complex chat, multilingual, reasoning and agent.
New family includes three cutting-edge models: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B.
WizardLM-2 is the latest milestone in our effort in scaling up LLM post-training. One year ago, we have been iterating on training of Wizard series since our first work on
Empowering Large Language Models to Follow Complex Instructions, then we accelerate the evolution to code and math reasoning scenarios.
Since then, Evol-Instruct and Instruction&Process Supervised Reinforcement Learning (RLEIF) have become fundamental technologies for GenAI community. Recently, we have further optimized our
methods and data quality, resulting in significant performance improvements, the outcome is WizardLM-2.
WizardLM-2 8x22B is our most advanced model, and the best opensource LLM in our internal evaluation on highly complex tasks.
WizardLM-2 70B reaches top-tier reasoning capabilities and is the first choice in the same size.
WizardLM-2 7B is the fastest and achieves comparable performance with existing 10x larger opensource leading models.
Following, we will introduce the overall methods and main experimental results, and the associated details and rethinking will be presented in our upcoming paper.
As the natural world's human-generated data becomes increasingly exhausted through LLM training, we believe that:
the data carefully created by AI and the model step-by-step supervised by AI will be the sole path towards more powerful AI.
In the past one year, we built a fully AI powered synthetic training system:
To present a comprehensive overview of the performance of WizardLM-2, we conduct both human and automatic evaluations between our models and diverse baselines.
As indicated in the following main experimental results, WizardLM-2 demonstrates highly competitive performance compared to those leading proprietary works
and consistently outperforms all the existing state-of-the-art opensource models. More associated details and thinking will be presented in our upcoming paper.
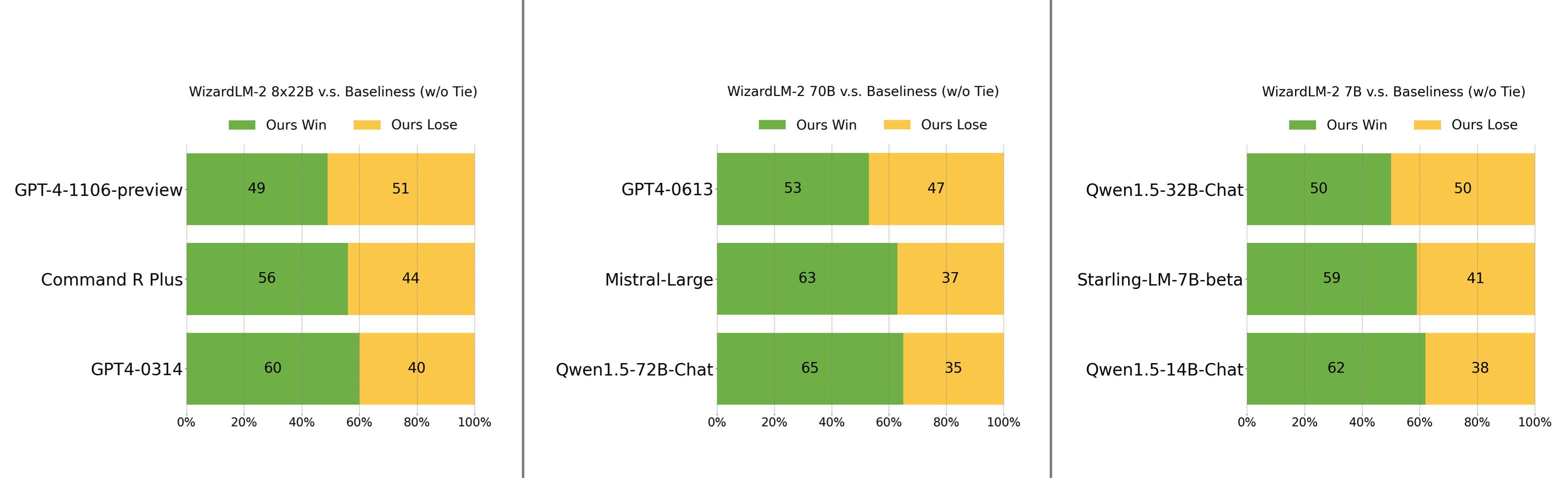
Human Preferences Evaluation
We carefully collected a complex and challenging set consisting of real-world instructions, which includes main requirements of humanity,
such as writing, coding, math, reasoning, agent, and multilingual. We perform a blind pairwise comparison between WizardLM-2 and baselines.
To each annotator, responses from all models are presented, which are randomly shuffled to hide their sources. We report the win:loss rate without tie:
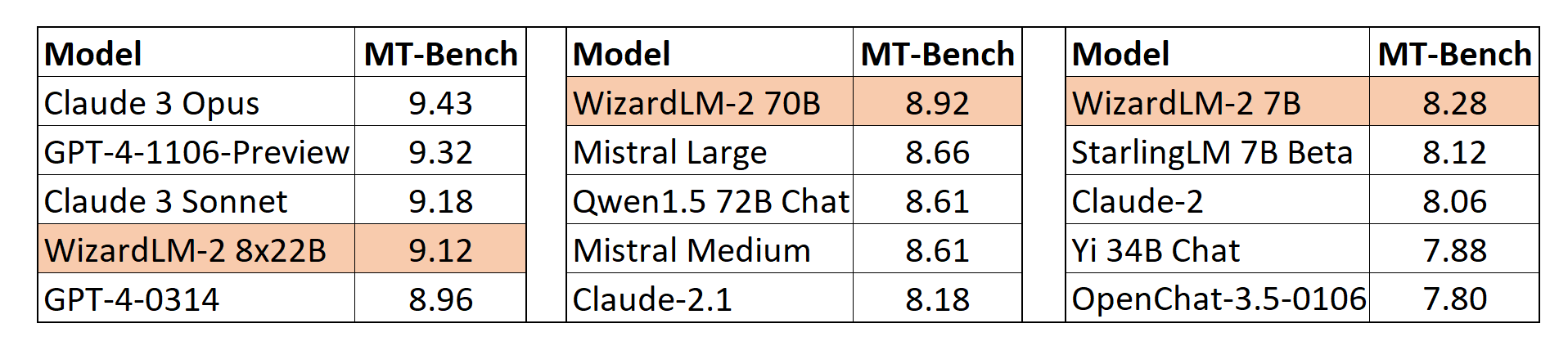
MT-Bench
We also adopt the automatic MT-Bench evaluation framework based on GPT-4 proposed by lmsys to assess the performance of models.
The WizardLM-2 8x22B even demonstrates highly competitive performance compared to the most advanced proprietary works such as GPT-4-Trubo and Glaude-3.
Meanwhile, WizardLM-2 7B and WizardLM-2 70B are all the top-performing models among the other leading baselines at 7B to 70B model scales.
Please use the same system prompts strictly with us to guarantee the generation quality.
❗Note for model system prompts usage:
WizardLM-2 adopts the prompt format from Vicuna and supports multi-turn conversation.
The prompt should be as following:
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>USER: Who are you? ASSISTANT: I am WizardLM.</s>......
The License of WizardLM-2 8x22B and WizardLM-2 7B is Apache2.0. The License of WizardLM-2 70B is Llama-2-Community.